Principes
Distribution et scalabilité
Les technologies Big Data sont distribuées, et répartissent le travail entre plusieurs machines en réseau.
Le Big Data nécessite des systèmes fortement scalables (capacité d’un système à augmenter ses performances et sa capacité de stockage). La scalabilité du Big-Data est horizontale (scale out) : les performances sont augmentées par l’ajout de nouvelles machines au réseau.
Bases NoSQL
Les bases de données NoSQL, distribuées par nature et scalables, sont privilégiées dans le Big Data.
Exemples de bases NoSQL : Redis, MongoDB, Cassandra, DynamoDB, HBase, Neo4j.
Framework Hadoop
Le framework Hadoop, créé en 2006, est la solution distribuée type pour le stockage et le traitement des données. Hadoop comporte à la base deux couches :

HDFS
HDFS (Hadoop Distributed File System) est un système de fichiers distribués.
La machine pilotant le réseau est le NameNode. Les autres machines sont les DataNodes ; elles stockent les données :
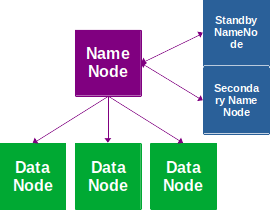
Un Secondary NameNode ou un Standby NameNode peuvent être ajoutés pour fiabiliser le réseau. Avec l’ajout d’un Standby NameNode, HDFS passe en mode HA (High Availability, Haute Disponibilité).
MapReduce
MapReduce est un moteur de traitement distribué, qui réalise un traitement global des données réparties sur plusieurs machines, avec :
- les opérations Map, pour filtrer et faire des opérations simples sur les données des DataNodes ;
- les opérations Reduce, pour réaliser des opérations d’agrégation et de synthèse sur les données produites par les Map.
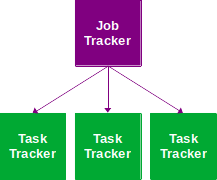
La machine distribuant les opérations de Map/Reduce est le Job Tracker. Les machines exécutant les opérations sont les Task Trackers :
Yarn
Hadoop a connu une série d’améliorations, avec notamment l’arrivée de Yarn en 2012 :

Yarn (Yet Another Resource Negotiator) est une couche intermédiaire, qui améliore la gestion de la distribution du traitement entre les nœuds du réseau et permet l’intégration d’autres moteurs de traitement comme Spark.